Experiment4
1.6 索引实验
1.6.1 实验目的
掌握索引设计原则和技巧,能够创建合适的索引以提高数据库查询、统计分析效率。
1.6.2 实验内容和要求
针对给定的数据库模式和具体应用需求,创建唯一索引、函数索引、复合索引等;修改索引;删除索引。设计相应的 SQL 查询验证索引有效性。学习利用 EXPLAIN 命令分析 SQL 查询是否使用了所创建的索引,并能够分析其原因,执行 SQL 查询并估算索引提高查询效率的百分比。要求实验数据集达到 10 万条记录以上的数据量,以便验证索引效果。
1.6.3 实验重点和难点
实验重点:创建索引。
实验难点:设计 SQL 查询验证索引有效性。
1.6.4 实验内容记录
1.6.4.1 创建唯一索引
- 对员工表的员工号码建立唯一索引
1
CREATE UNIQUE INDEX idx_emp_no ON employees (emp_no);

注:主码列在创建表时会自动创建相应的索引。
注:在存在数据时,建立索引需要一定的时间。
1.6.4.2 创建复合索引
- 对员工表的名字建立复合索引
1
CREATE INDEX idx_name ON employees (first_name, last_name);

1.6.4.3 创建长度函数索引
MYSQL 函数索引暂不录入。
1.6.4.4 创建聚簇索引
MYSQL Innodb 不支持单独建立聚簇索引。在此不列出。
1.6.4.5 创建 HASH 索引
- 对员工的雇佣日期创建 HASH 索引
1
CREATE INDEX idx_hash_hiredate USING HASH ON employees (hire_date);

注:MYSQL 创建 HASH 索引的语法和书中给出的语法稍有不同。
1.6.4.6 修改索引名称
注:修改索引名称通过先删除再添加实现。
1.6.4.7 查询表上的已有索引
- 查询员工表上的已有索引
1
2
3
4
5
6
7
8
9
10
11SHOW INDEX FROM employees;
MariaDB [employees]> SHOW INDEX FROM employees;
+-----------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-----------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| employees | 0 | PRIMARY | 1 | emp_no | A | 299290 | NULL | NULL | | BTREE | | |
| employees | 0 | idx_emp_no | 1 | emp_no | A | 299290 | NULL | NULL | | BTREE | | |
| employees | 1 | idx_name | 1 | first_name | A | 2672 | NULL | NULL | | BTREE | | |
| employees | 1 | idx_name | 2 | last_name | A | 299290 | NULL | NULL | | BTREE | | |
| employees | 1 | idx_hash_hiredate | 1 | hire_date | A | 10688 | NULL | NULL | | BTREE | | |
+-----------+------------+-------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1.6.4.8 分析某个 SQL 语句执行时是否使用了索引
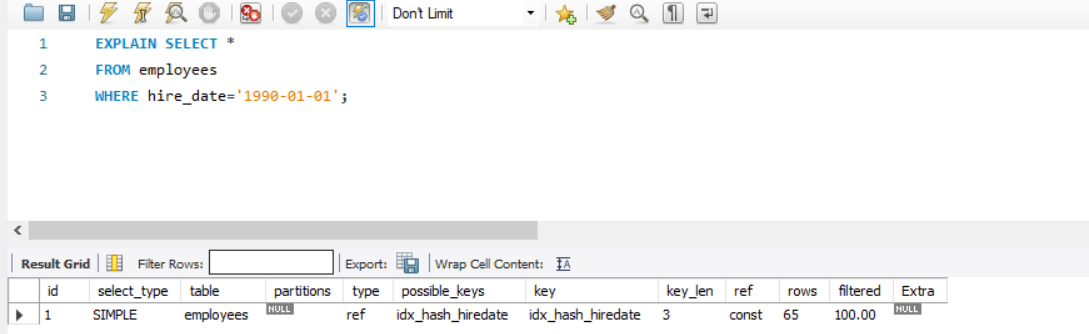
- 分析从员工表上查询某个日期雇佣的员工是否使用了索引。得到结果如下:
1
EXPLAIN SELECT * FROM employees WHERE hire_date='1990-01-01';
1
MariaDB [employees]> EXPLAIN SELECT * FROM employees WHERE hire_date='1990-01-01'; +------+-------------+-----------+------+-------------------+-------------------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-----------+------+-------------------+-------------------+---------+-------+------+-------+ | 1 | SIMPLE | employees | ref | idx_hash_hiredate | idx_hash_hiredate | 3 | const | 65 | | +------+-------------+-----------+------+-------------------+-------------------+---------+-------+------+-------+ 1 row in set (0.00 sec)
1.6.4.9 验证索引效率
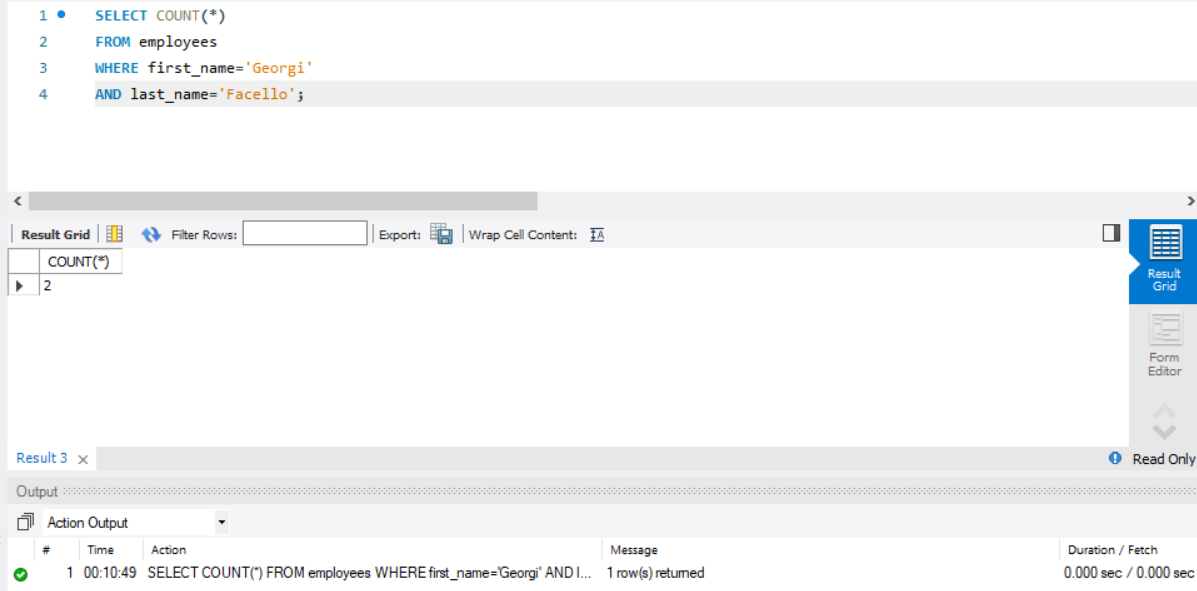
首先验证复合索引,在有索引的情况下,统计指定名字的员工数目。
1 | SELECT COUNT(*) FROM employees WHERE first_name='Georgi' AND last_name='Facello'; |
得到结果为:
1 | +----------+ |
然后去掉复合索引,再次执行,结果为:
1 | +----------+ |
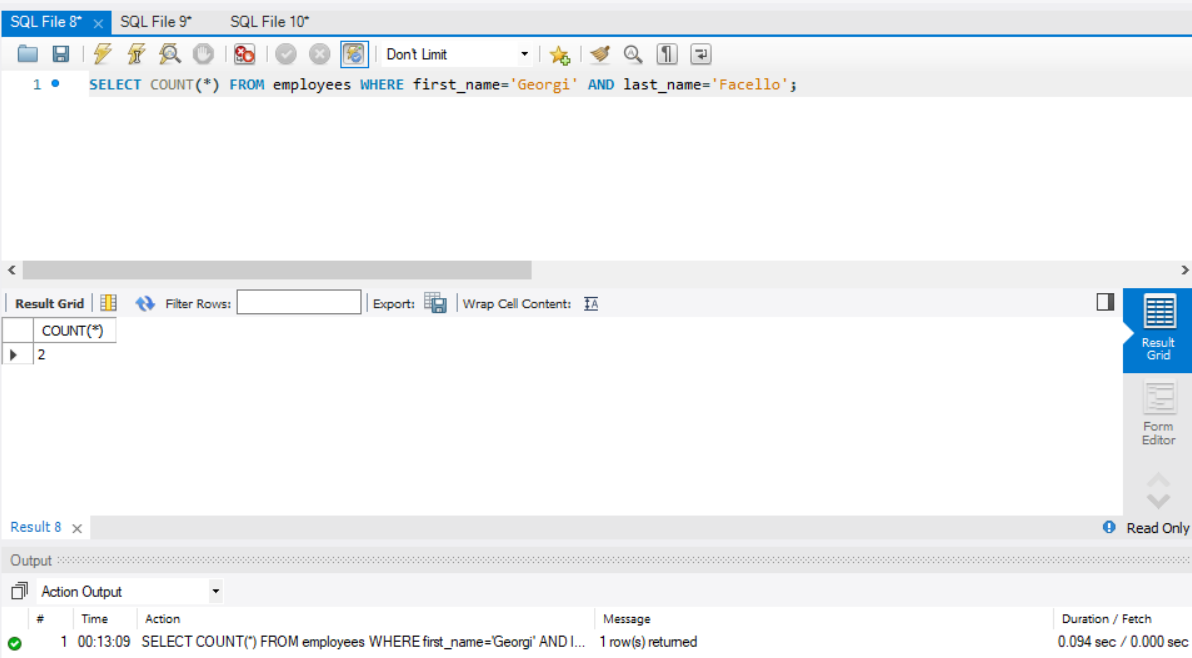
结果显示复合索引提高了查询效率。
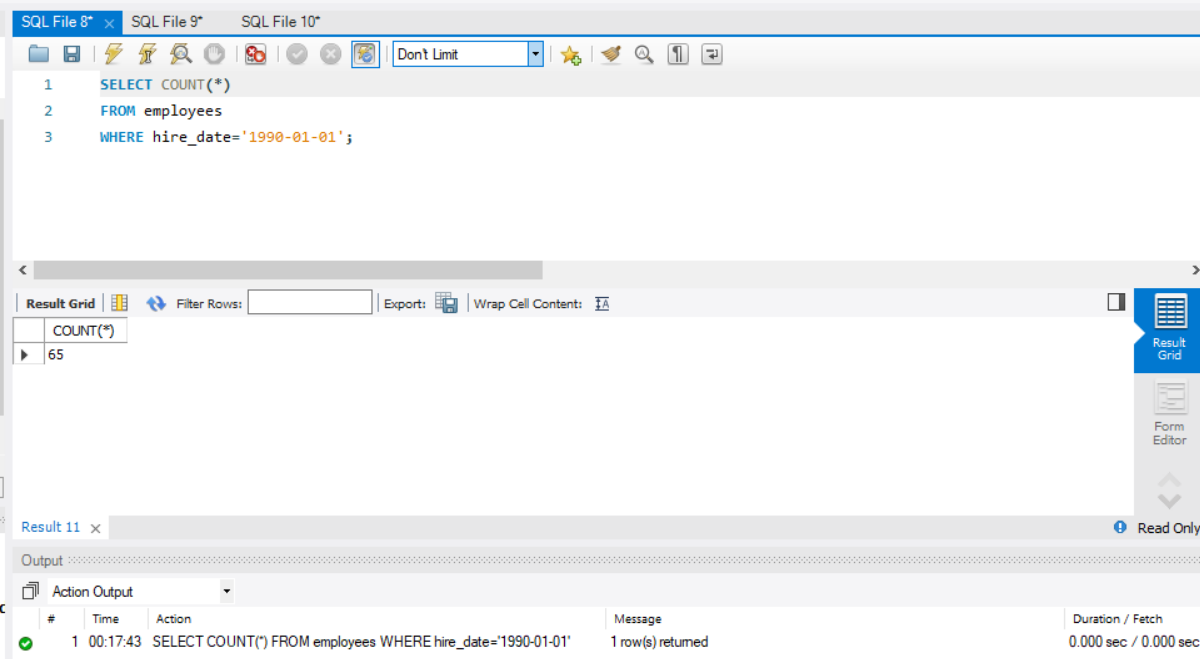
然后验证哈希索引,在有索引的情况下,统计指定雇佣日期的员工数目。
1 | SELECT COUNT(*) FROM employees WHERE hire_date='1990-01-01'; |
结果为:
1 | +----------+ |
去掉索引,然后在查询,结果为:
1 | +----------+ |
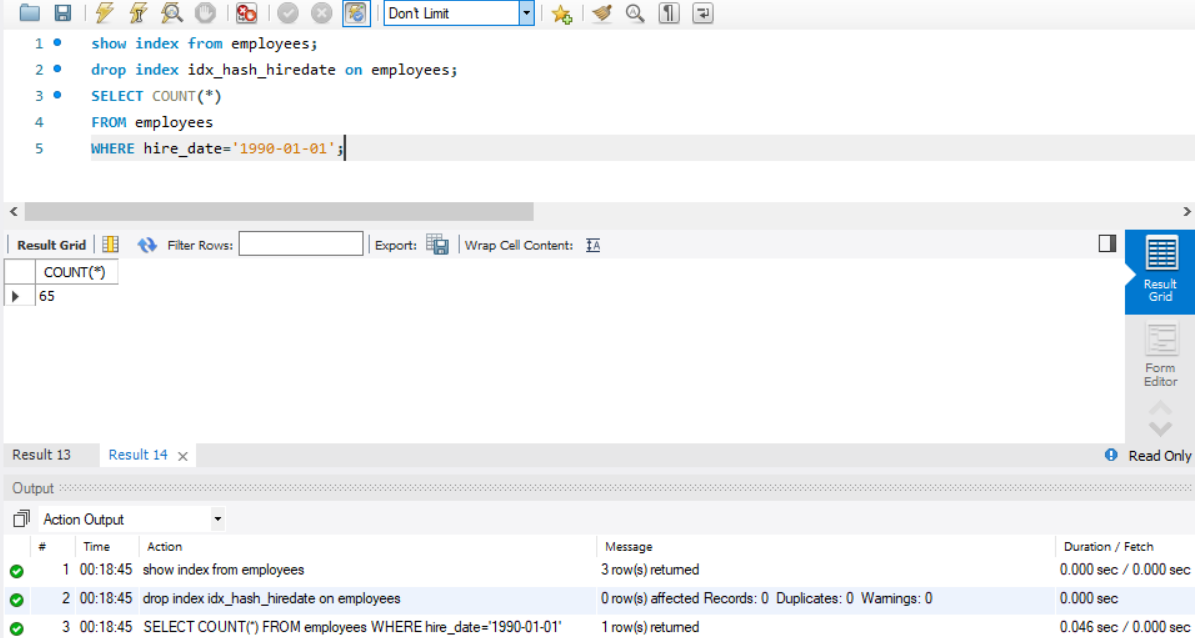
结果显示哈希索引提高了查询效率。
1.6.5 思考
- 在一个表的多个字段上创建的复合索引,与在相应的每个字段上创建的多个简单索引有何异同?请设计相应的例子加以验证。
可以直接创建两个在名字上的简单索引然后测试即可。
1 | CREATE INDEX idx_first_name |
执行结果为:
1 | +------+-------------+-----------+-------------+------------------------------+------------------------------+---------+------+------+-------------------------------------------------------------------------+ |
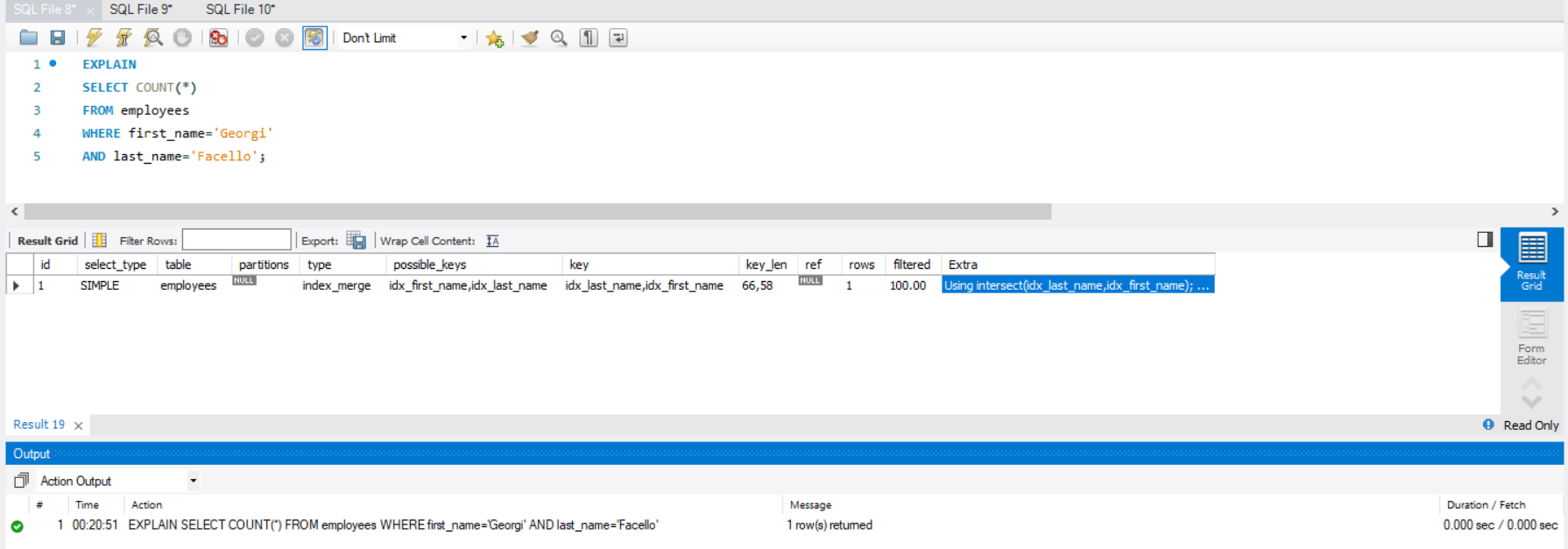
也即 MYSQL 内部和执行了对多个单列索引合并为一个复合索引的优化,此时效率不受影响。
对于已定义的复合索引,从最左侧开始的列是可用的,例如:
1 | EXPLAIN SELECT COUNT(*) FROM employees WHERE last_name='Facello'; |
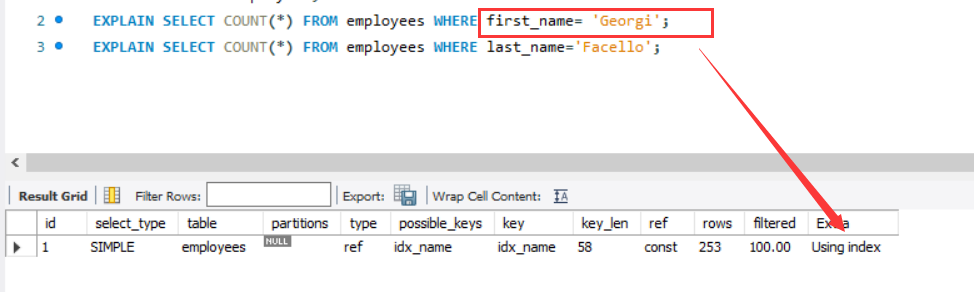
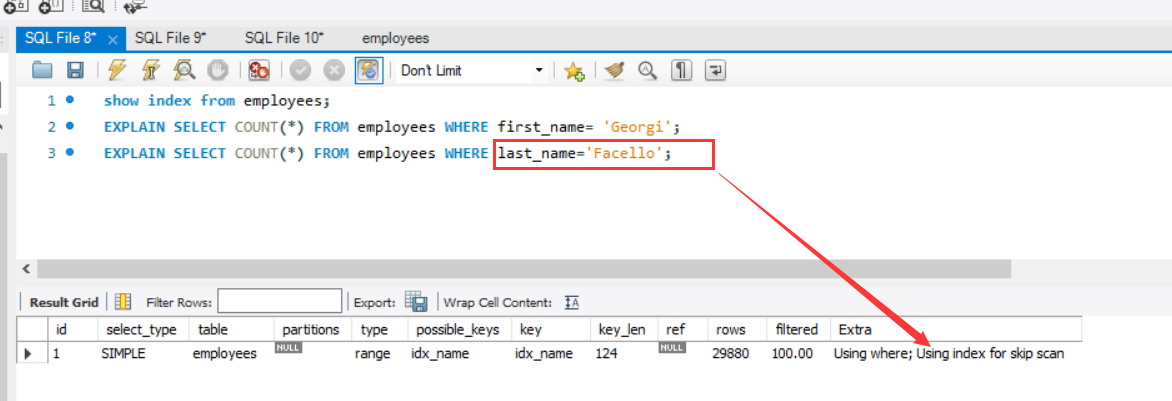
这里在已定义了复合索引的情况下只查询第二个条件,发现索引没有被采用,而是进行了全表扫描。
聚合索引
查询时使用联合索引的一个字段,如果这个字段在联合索引中所有字段的第一个,那就会用到索引,否则就无法使用到索引。
例如你有一个 学生表。
字段包含 学号, 班级, 姓名,性别, 出生年月日。
你创建一个 组合索引 ( 班级, 姓名)
那么
1 | SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' |
将使用索引。
1 | SELECT * FROM 学生表 WHERE 班级='2010级3班' |
将使用索引。
1 | SELECT * FROM 学生表 WHERE 姓名='张三' |
将不使用索引。
单独索引
删除掉上面的索引
再创建两个 独立索引
索引1 ( 班级)
索引2 ( 姓名)
那么
1 | SELECT * FROM 学生表 WHERE 班级='2010级3班' AND 姓名='张三' |
将根据数据库的分析信息, 自动选择使用索引1或者索引2中的一个 (理论上会使用 索引2, 因为 姓名=张三的人少, 优先找到所有 姓名为 张三的人以后, 然后再从这些数据中, 找班级 = ‘2010级3班‘的
1 | SELECT * FROM 学生表 WHERE 班级='2010级3班' |
将使用索引1 .
1 | SELECT * FROM 学生表 WHERE 姓名='张三' |
将使用索引2。