Experiment3
1.3 数据高级查询实验
1.3.1 实验目的
掌握 SQL 嵌套查询和集合查询等各种高级查询的设计方法等。
1.3.2 实验内容和要求
针对 TPC-H 数据库,正确分析用户查询要求,设计各种嵌套查询和集合查询。
1.3.3 实验重点和难点
实验重点:嵌套查询。
实验难点:相关子查询、多层 EXIST 嵌套查询。
1.3.4 实验内容记录
1.3.4.1 IN 嵌套查询
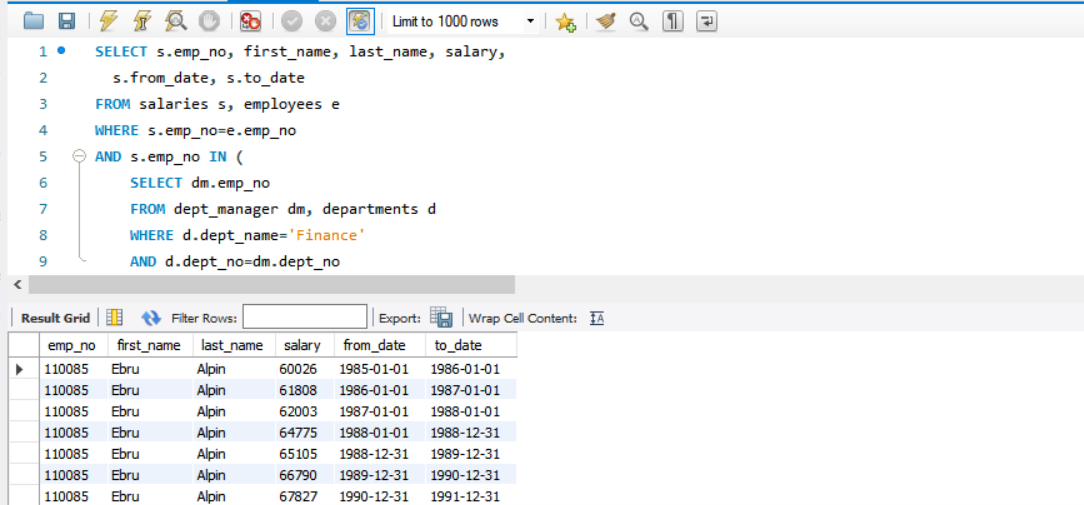
- 查询财务部门经理的工资记录。
1
2
3
4
5
6
7
8
9
10SELECT s.emp_no, first_name, last_name, salary,
s.from_date, s.to_date
FROM salaries s, employees e
WHERE s.emp_no=e.emp_no
AND s.emp_no IN (
SELECT dm.emp_no
FROM dept_manager dm, departments d
WHERE d.dept_name='Finance'
AND d.dept_no=dm.dept_no
);
1.3.4.2 单层 EXISTS 嵌套查询
注:带 EXISTS 谓词的子查询不一定能被其它形式的子查询等价替换。
- 统计(曾经)在财务部门的员工数量。
使用 EXISTS 谓词可以理解为找出这样的员工,该员工存在部门为财务的元组。
1 | SELECT COUNT(DISTINCT de.emp_no) |
如果用两表连接查询,可以实现相似的语义(语义存在细微区别,前者是存在语义,后者是计数语义)。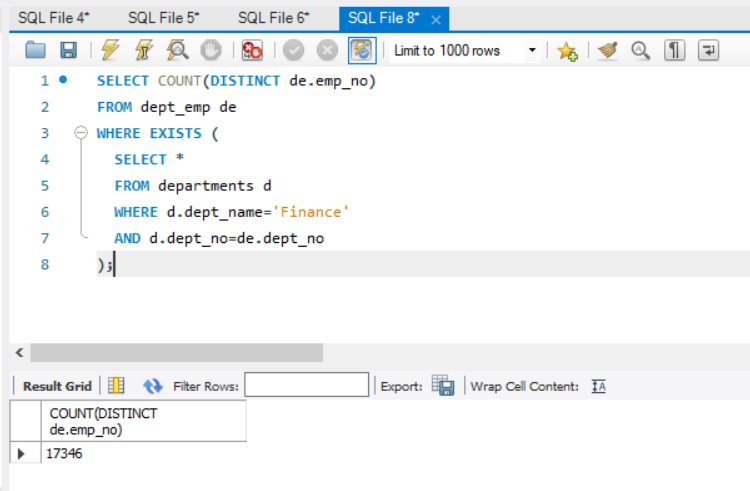
1 | SELECT COUNT(DISTINCT de.emp_no) |
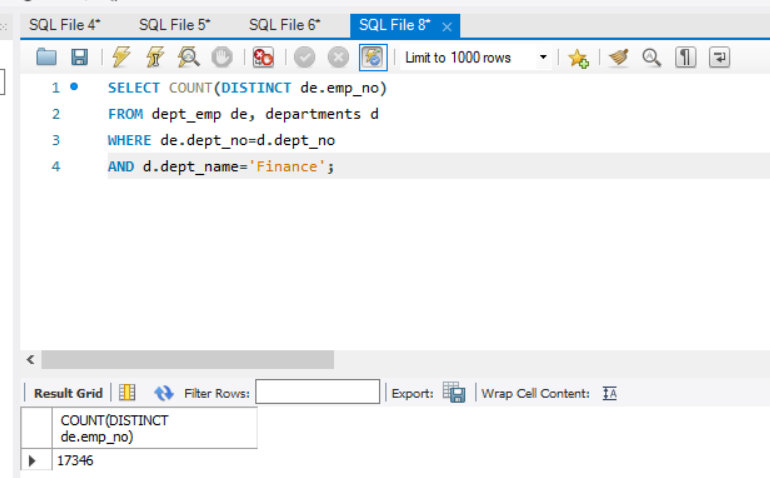
1.3.4.3 两层 EXISTS 嵌套查询
注意:SQL 查询的结果是一个集合,实际上就是一层全称谓词。如果给出的条件中再出现全称谓词,则可以转换为存在谓词进行查询。
注意:嵌套查询如果进行了相关查询,则实际上就是一个外层和内层进行笛卡尔积然后对结果集合进行筛选(嵌套内层进行筛选)的过程。
- 查询(曾经)在所有部门待过的员工。
转换为,不存在这样的部门,员工没有待过。
1 | SELECT emp_no |
- 要先看select的语句代表的含义
SELECT * FROM departments d选择所有的部门 – 可以理解为遍历所有的部门SELECT * FROM dept_emp de WHERE d.dept_no=de.dept_no AND e.emp_no=de.emp_no选择某个员工在某个部门的工作信息
- 直观理解:从
not exists的语义上理解:不存在一个部门,该员工没有待过(没有工作信息) ->要查找在所有部门都工作过的员工 - 从内到外理解:对于每一个员工e,检查每一个部门d,判断有无工作记录
- 第二层子查询:判断有无工作记录,如果没有工作记录,第六行的
not exists返回为true-> 存在这样一个部门d,该员工在该部门没有工作信息 ->第一层子查询返回的结果不是为空,第三行的not exists为false,因此第一行的selcet就不会执行 - 第二层子查询:如果有工作记录,第六行的
not exists返回为false-> 不存在这样一个部门d,该员工在该部门没有工作信息 ,第一层子查询中的select不会执行 -> 该员工在部门d中有工作过,但是无法保证在其他部门也有工作记录,所以第一层子查询会挑选一个新的部门d后,重新进入第二层子查询判断 -> 全部判断完后,如果仍然没有部门,说明第三行第三行的not exists为true,因此第一行的selcet就会执行 ->得到想要的结果
- 第二层子查询:判断有无工作记录,如果没有工作记录,第六行的
1.3.4.4 FROM 子句中的嵌套查询
FROM 子句中进行嵌套是将嵌套块生成临时表进行查询。
- 统计所有员工的平均总工资。
首先需要一张员工的总工资表,然后根据总工资表进行平均数计算。
1 | SELECT SUM(total_salary)/COUNT(DISTINCT total_emp_no) avg |
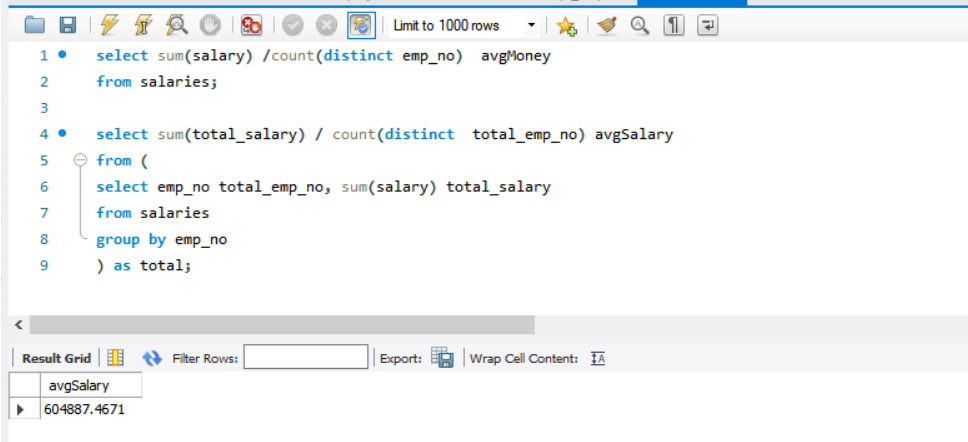
1.3.4.5 集合查询(交、并、差)
与集合运算的要求一致,集合查询时进行集合运算的集合必须具有相同的列数以及对应有相同的数据类型。
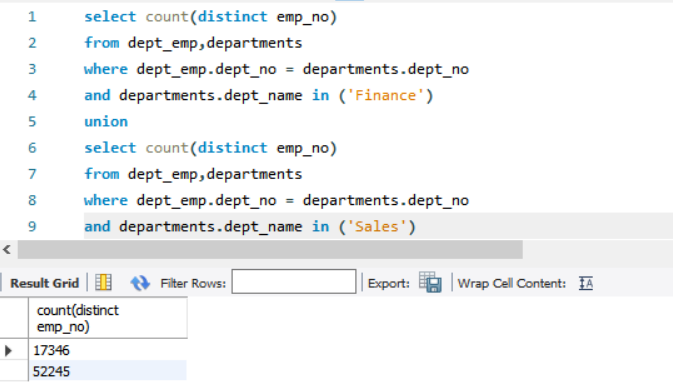
统计财务(Finance)部门和销售(Sales)部门的历史员工数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT COUNT(DISTINCT emp_no)
FROM dept_emp de, departments d
WHERE de.dept_no=d.dept_no
AND d.dept_name IN ('Finance')
UNION
SELECT COUNT(DISTINCT emp_no)
FROM dept_emp de, departments d
WHERE de.dept_no=d.dept_no
AND d.dept_name IN ('Sales');
+------------------------+
| COUNT(DISTINCT emp_no) |
+------------------------+
| 17346 |
| 52245 |
+------------------------+
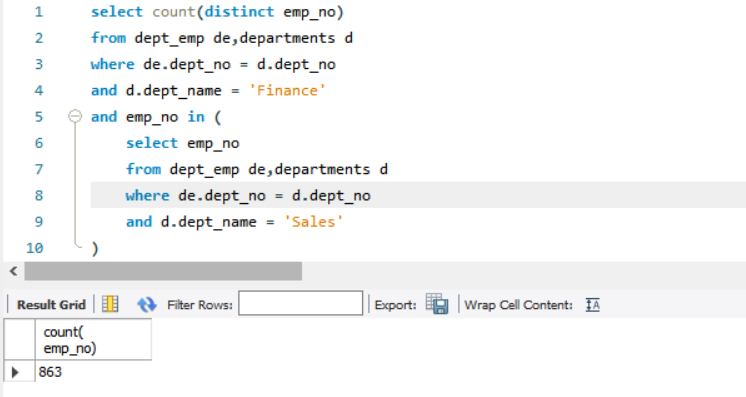
查询在财务(Finance)部门和销售(Sales)部门都工作过的员工。
注:MYSQL 目前不支持交运算。
1 | SELECT DISTINCT de.emp_no |
模拟交运算
1 | select count(distinct emp_no) |
1.3.5 思考
试分析什么类型的查询可以用连接查询实现,什么类型的查询只能用嵌套查询实现?
连接查询在算法实现上,一定可以通过嵌套循环实现,因此连接查询一定能被嵌套查询等价替换。由于嵌套查询在嵌套条件上提供了一些语义,因此嵌套查询不一定能被转换为连接查询。
从语义上看,连接查询首先是对两个表进行笛卡尔积运算(不带条件的),然后对得到的元组集合进行条件筛选,因此连接查询适用于需要将多个表的属性关联起来的查询需求。嵌套查询则是外层表和内层表进行嵌套罗列,嵌套时可以使用 IN、ANY、ALL、EXISTS 谓词。这些谓词的使用使得嵌套查询语义不一定能被连接查询实现。
连接查询在算法实现上不一定需要通过嵌套循环实现,因此效率往往高于嵌套查询。如:
统计在财务(Finance)部门的员工人数。
1 | SELECT COUNT(e.emp_no) |
可以看出来,三个表的连接查询相比三个表的嵌套查询在速度上要快很多。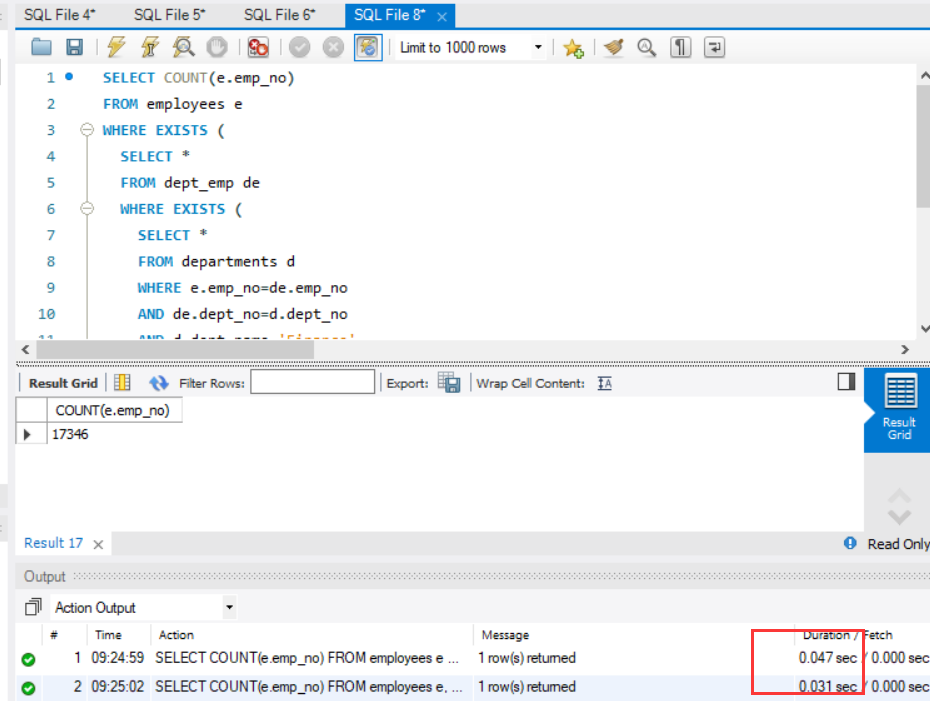
试分析不相关子查询和相关子查询的区别。
两者区别在于子查询是否引用外层查询的属性。若不引用,则两个查询完全隔离,相当于是两个独立的查询。
从实现上看,相关子查询由于存在相关引用,因此子查询被执行多次,而不相关子查询由于是一个独立的查询,因此只执行一次。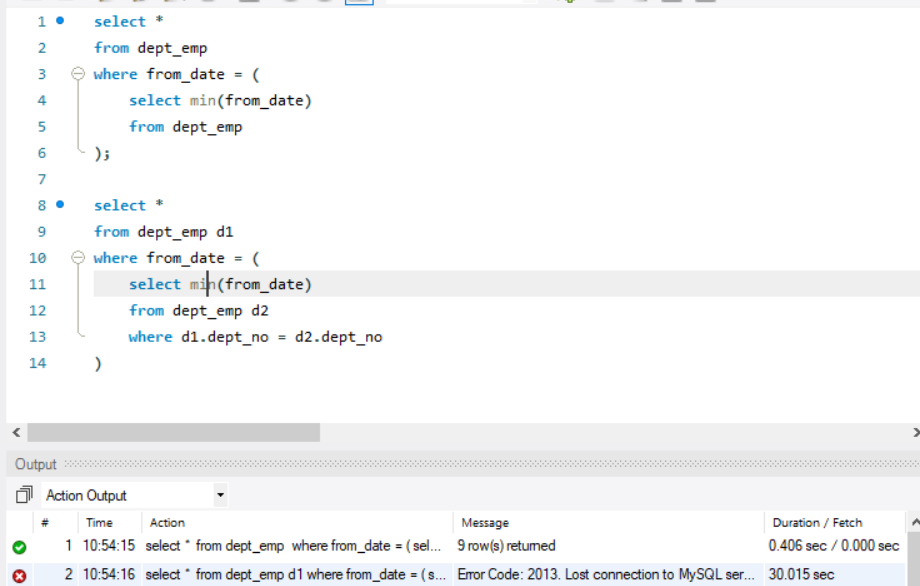
相关子查询因为耗时过长,导致出现错误。
说明不相关子查询效率高于相关子查询。相关子查询可以嵌套在多个层次中,但是嵌套层次越多,效率越低。
1.4 数据更新实验
1.4.1 实验目的
熟悉数据库的数据更新操作,能够使用 SQL 语句对数据库进行数据的插入、修改、删除操作。
1.4.2 实验内容和要求
针对 employees 数据库设计单元组插入、批量修改插入、修改数据和删除数据等 SQL 语句。理解和掌握 INSERT、UPDATE 和 DELETE 语法结构的各个组成成分,结合嵌套 SQL 子查询,分别设计几种不同形式的插入、修改和删除的语句,并调试成功。
1.4.3 实验重点和难点
实验重点:插入、修改和删除数据的 SQL。
实验难点:与嵌套 SQL 子查询相结合的插入、修改和删除数据的 SQL 语句;利用一个表的数据来插入、修改和删除另外一个表的数据。
1.4.4 实验内容记录
1.4.4.1 INSERT 基本语句
插入一条雇员记录。
1 | INSERT INTO employees |
1.4.4.2 批量数据 INSERT 语句
- 创建一个男员工表和女员工表,并将所有男员工插入到男员工表,将所有女员工插入到女员工表。
先创建两张表。
1 | CREATE TABLE employees_female |
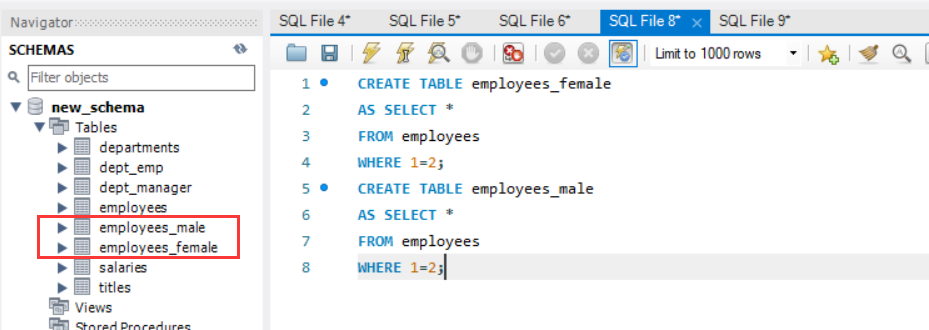
注:这里的条件永不满足,用来复制表模式,而不复制任何数据。
然后将数据录入两张表。
1 | INSERT INTO employees_female |
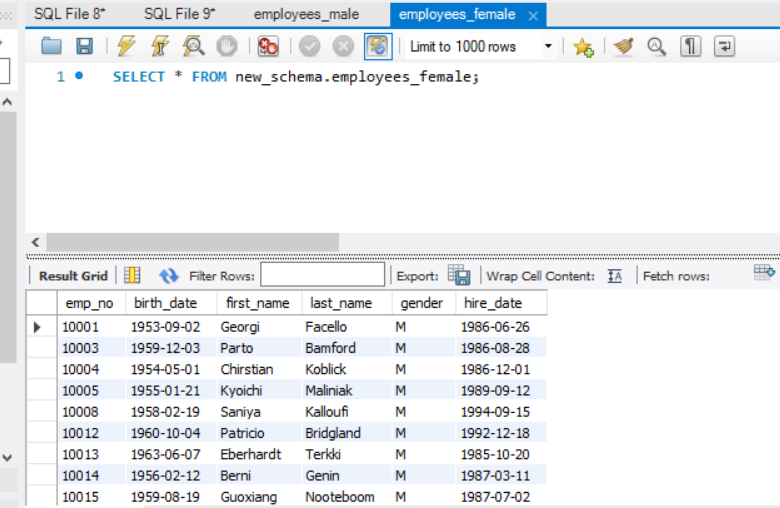
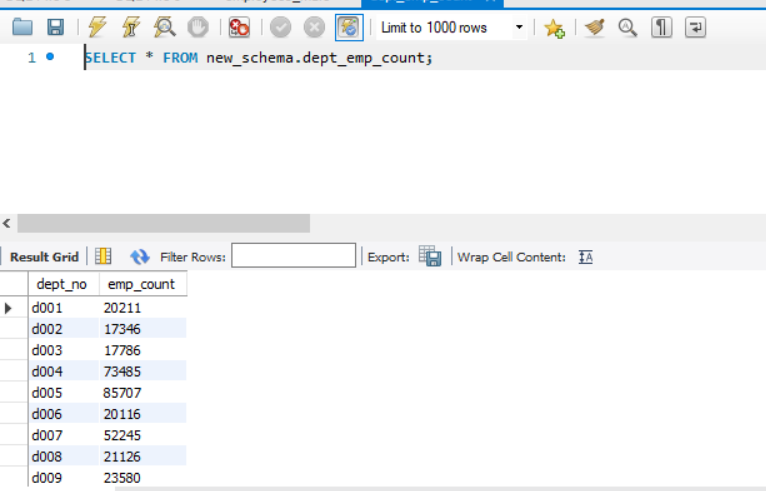
- 创建一个部门员工人数统计表,并统计所有部门的历史员工人数。
先创建表。
1 | CREATE TABLE dept_emp_count( dept_no CHAR(4), emp_count INT); |
然后批量录入数据。
1 | INSERT INTO dept_emp_count |
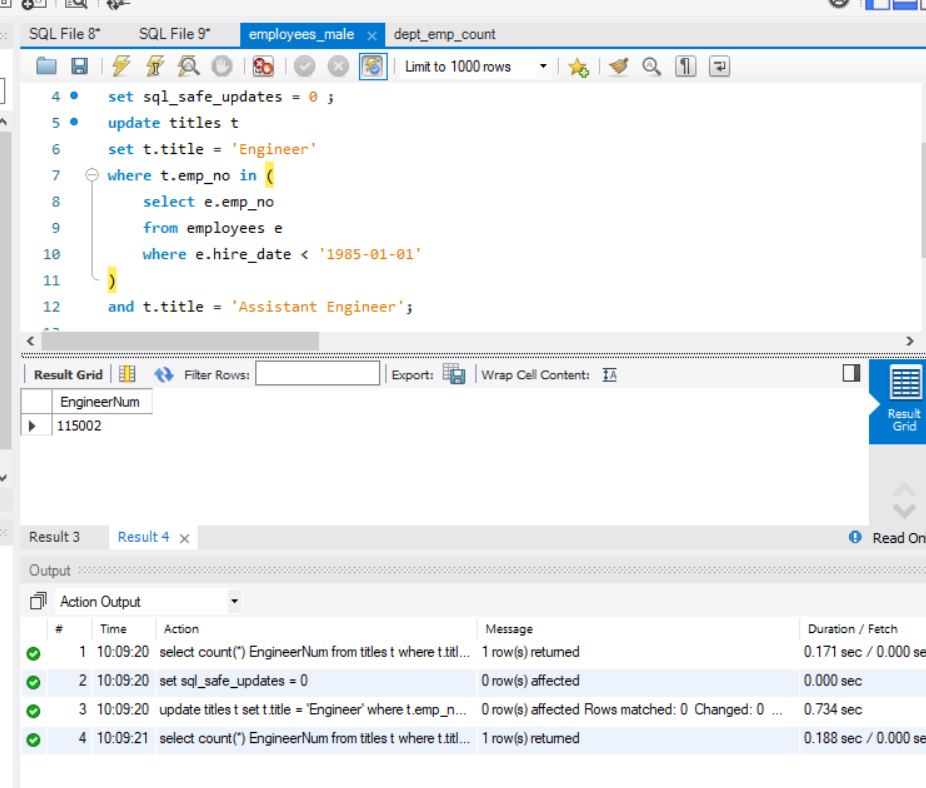
1.4.4.3 UPDATE 语句(修改部分记录的部分列值)
- 将所有 1985 年及以前入职,职位为 Assistant Engineer 的员工的职位修改为 Engineer 。
1
2
3
4
5
6
7update titles t
set t.title = 'Engineer'
where t.emp_no in (
select e.emp_no
from employees e
where e.hire_date < '1985-01-01'
)
1.4.4.4 UPDATE 语句(利用一个表的数据更新另一个表的数据)
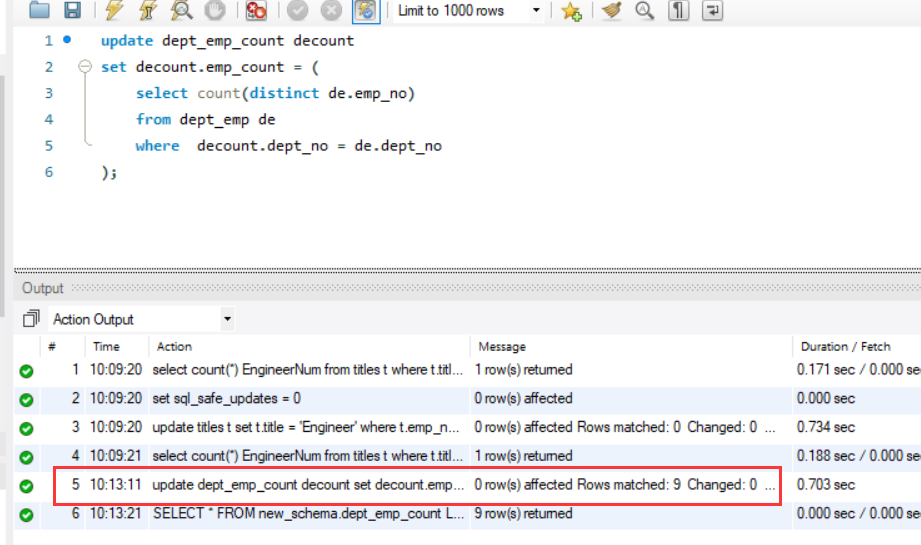
- 更新部门员工人数统计表(假设表已经存在)。
1
2
3
4
5
6UPDATE dept_emp_count decount
SET decount.emp_count = (
SELECT COUNT(DISTINCT de.emp_no)
FROM dept_emp de
WHERE de.dept_no=decount.dept_no
);
1.4.4.5 DELETE 基本语句(删除给定条件的所有记录)
- 删除 2000 年以前的工资记录。
1
2
3DELETE FROM salaries
WHERE from_date < '2000-01-01'
AND to_date < '2000-01-01';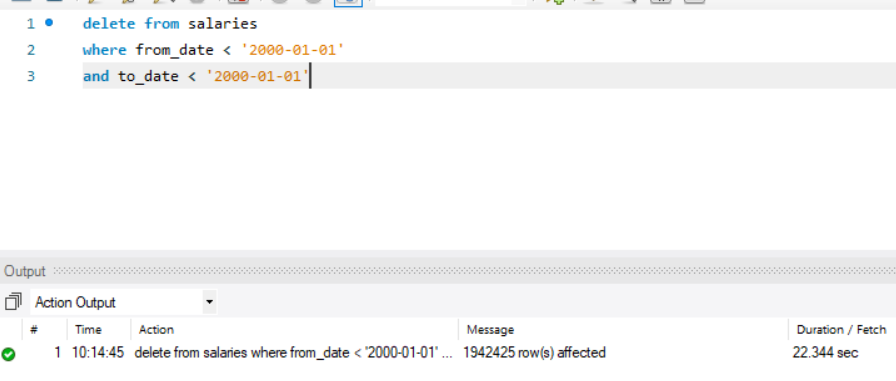
1.4.5 思考
请分析数据库模式更新和数据更新 SQL 语句的异同。
两者的关键字不同,更新模式使用 ALTER TABLE ,更新数据使用 UPDATE 。
数据库模式更新用到的 sql 语句有 create, drop, alter 等,它们可以创建或者删除表、视图、索引等对象,或者修改它们的属性或者约束。
数据更新用到的 sql 语句有 insert, update, delete 等,它们可以向表中插入新的记录,或者修改或者删除已有的记录。
请分析数据库系统除了 INSERT、UPDATE 和 DELETE 等基本的数据更新语句之外,还有哪些可以用来更新数据库基本表数据的 SQL 语句?
如 truncate 。
merge into 语句,可以根据一个表或者视图中的数据,对另一个表中的数据进行插入、修改或者删除操作。
truncate 语句,可以快速地删除表中的所有数据,但是不影响表的结构和约束。
drop 语句,可以删除整个表及其相关的对象,例如索引、触发器等。
这些 sql 语句在不同的数据库系统中可能有不同的用法和限制,您需要根据您使用的数据库系统来选择合适的语句。
merge into 语句的基本语法是:
1 | merge into 目标表 |
其中,目标表和源表可以是实际的表、视图或者子查询,匹配条件是用来判断两个表中的数据是否相同的条件,update 和 insert 是用来指定当数据匹配或者不匹配时要执行的操作。
- 如果目标表有源表没有的数据,则保留该部分数据
- 如果源表有目标表没有的数据,触发
not matched进行插入 - 如果源表的数据和目标表的数据相同,触发
matched进行更新
1.5 视图实验
1.5.1 实验目的
熟悉 SQL 语言有关视图的操作,能够熟练使用 SQL 语句来创建需要的视图,定义数据库外模式,并能使用所创建的视图实现数据管理。
1.5.2 实验内容和要求
针对给定的数据库模式,以及相应的应用需求,创建视图和带 WITH CHECK OPTION 的视图,并验证 WITH CHECK OPTION 选项的有效性。理解和掌握视图消解执行原理,掌握可更新视图和不可更新视图的区别。
1.5.3 实验重点和难点
实验重点:创建视图。
实验难点:可更新的视图和不可更新的视图之区别,WITH CHECK OPTION 的验证。
1.5.4 实验内容记录
1.5.4.1 创建视图(省略视图列名)
- 创建男性员工视图。
1
2
3
4CREATE VIEW v_emploree_male AS
SELECT *
FROM employees e
WHERE e.gender='M';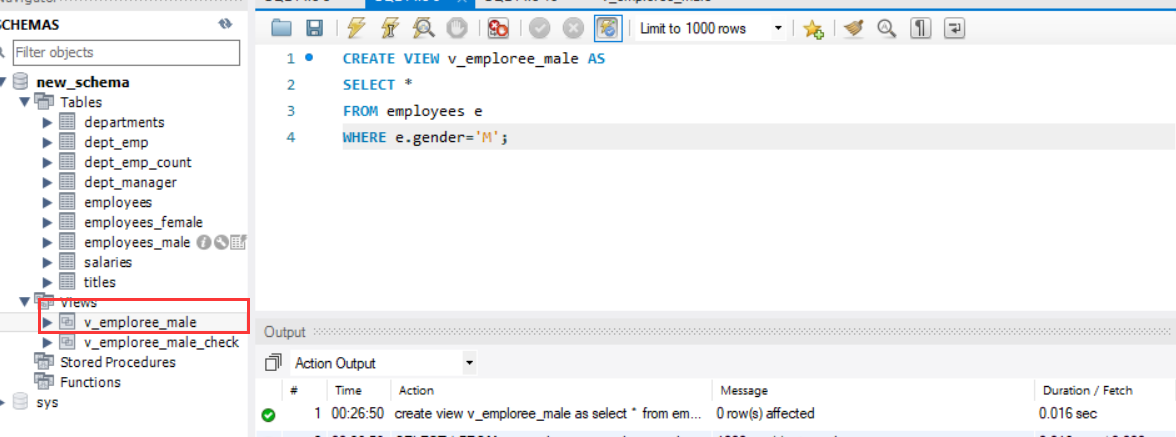
1.5.4.2 创建视图(不能省略列名的情况)
如果目标列不是单纯的属性名(如聚集函数或表达式),则应该给出列名。
- 创建部门历史员工总数的视图。
1
2
3
4CREATE VIEW v_dept_emp_num(dept_no, emp_count) AS
SELECT dept_no, COUNT(DISTINCT emp_no)
FROM dept_emp
GROUP BY dept_no;
1.5.4.3 创建视图(WITH CHECK OPTION)
WITH CHECK OPTION 使得在对视图进行操作时,会验证操作是否符合视图的条件。
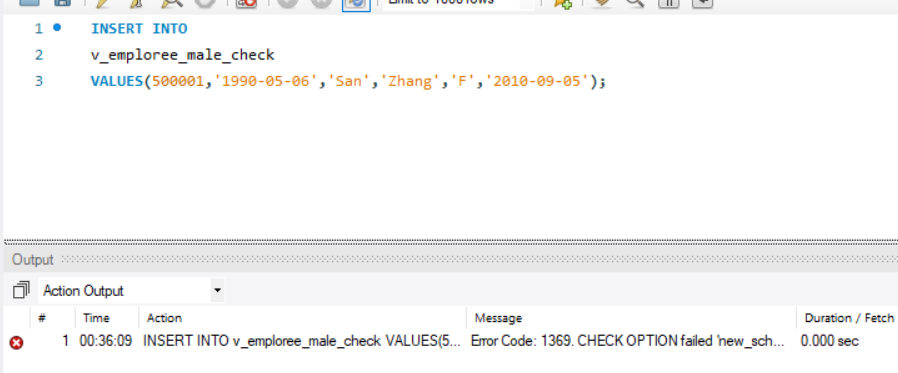
例如,对男性员工视图进行插入操作,插入一个女员工信息:
1 | INSERT INTO |
由男性员工视图没有 WITH CHECK OPTION 语句,因此插入成功,这使得视图的封装性被破坏。
加入选项:
1 | CREATE VIEW v_emploree_male_check AS |
再执行插入:
1 | INSERT INTO |
会得到错误:
1 | ERROR 1369 (HY000): CHECK OPTION failed 'employees.v_emploree_male_check' |
1.5.4.4 不可更新视图
如果为行列子集视图,则一定是可以更新的(如男性员工视图)。
如果不是,则不一定可以更新,如属性为聚集函数或表达式(如部门员工总数视图)。
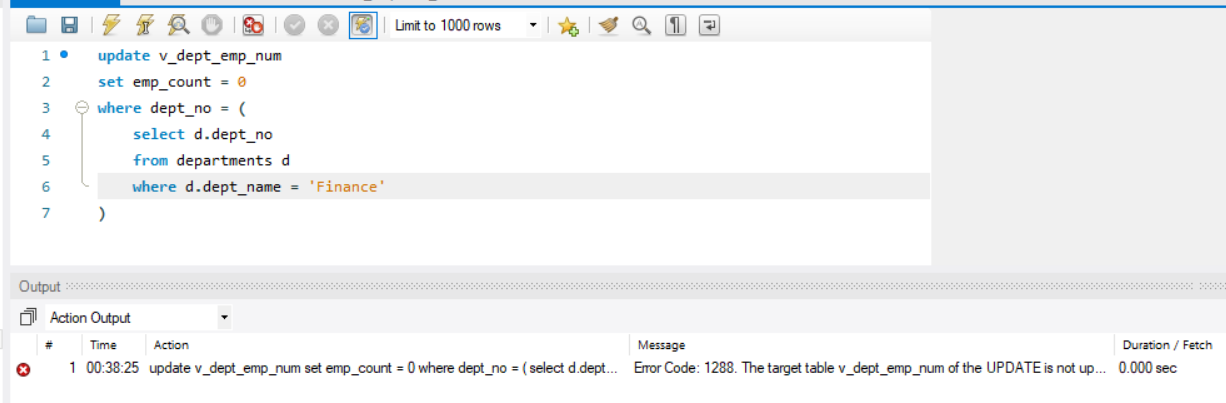
- 尝试修改财务(Finance)部门员工总数为 0 并观察报错。
1
2
3
4
5
6
7UPDATE v_dept_emp_num vden
SET emp_count=0
WHERE vden.dept_no=(
SELECT d.dept_no
FROM departments
WHERE d.dept_name='Finance'
);得到报错:1
Error Code: 1064. You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'dept_emp' at line 1
1
ERROR 1288 (HY000): The target table vden of the UPDATE is not updatable
1.5.4.5 删除视图
删除未被引用的视图,直接删除即可。
- 删除部门员工总数视图和男性员工视图。
1
2DROP VIEW v_dept_emp_num;
DROP VIEW v_emploree_male;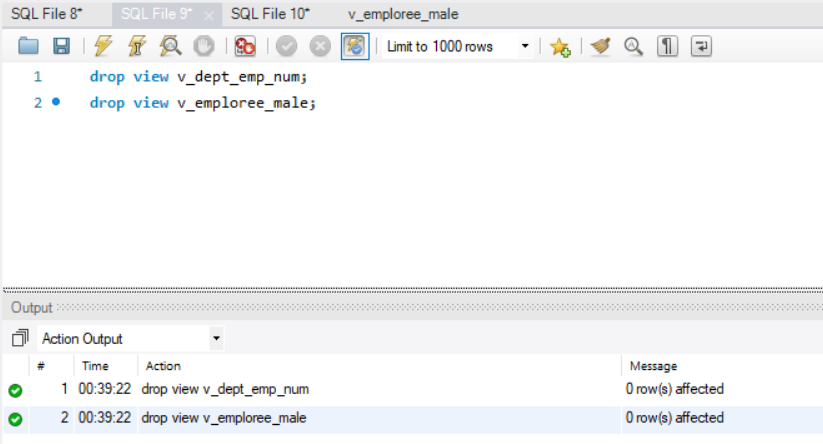
删除视图时 CASCADE 语句的作用:
先建立两个视图:直接删除 v_e_1,1
2
3
4
5
6CREATE VIEW v_e_1 AS
SELECT emp_no,birth_date,gender
FROM employees;
CREATE VIEW v_e_2 AS
SELECT emp_no,gender
FROM v_e_1;对于 MYSQL ,删除成功,但是会引起 v_e_2 查询报错。1
DROP VIEW v_e_1;
1
ERROR 1356 (HY000): View 'employees.v_e_2' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them
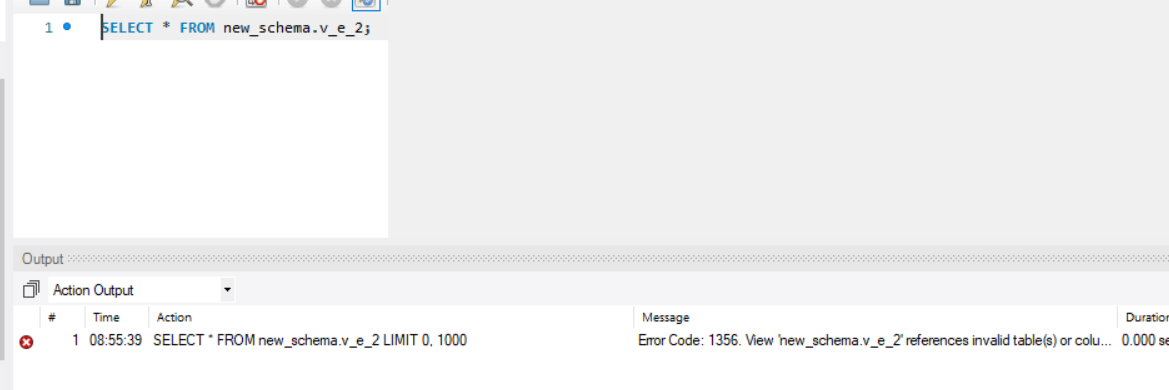
不论使用RESTRICT 短语还是 CASCADE 短语结果都是一样。
1.5.5 思考
- 请分析视图和基本表在使用方面有哪些异同,并设计相应的例子加以验证。
视图的数据来源于最原始的基本表,也即视图本身不存放数据。
视图不一定都是可以修改的。
- 请具体分析修改基本表的结构对相应的视图会产生何种影响?
修改基本表后,可能导致视图不能正常工作。
先创建一个测试表:
1 | CREATE TABLE d1 |
并创建基于测试表的一个视图:
1 | CREATE VIEW v_d1 AS |
然后调整测试表的结构,这里先尝试调整列的数据类型:
1 | ALTER TABLE d1 |
1 | Error Code: 1366. Incorrect integer value: 'd009' for column 'dept_no' at row 1 |
调整会触发警告,数据变为 0 。相应的视图也会同步改变。
如果删除一列:
1 | ALTER TABLE d1 |
此时查询视图会报告错误。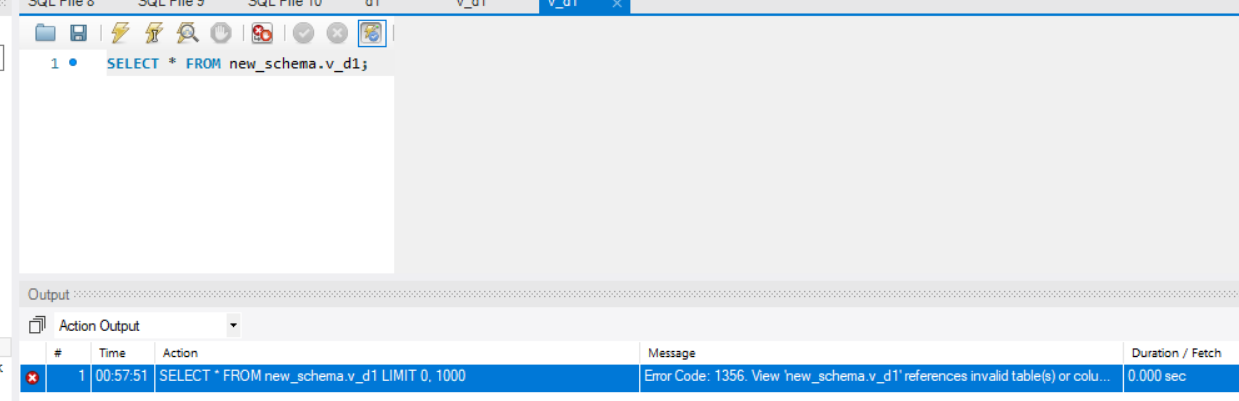
1 | Error Code: 1356. View 'new_schema.v_d1' references invalid table(s) or column(s) or |