Experiment2
1.2.1 实验目的
掌握 SQL 程序设计基本规范,熟练运用 SQL 语言实现数据基本查询,包括单表查询、分组统计查询和连接查询。
1.2.2 实验内容和要求
针对 TPC-H 数据库设计各种表单查询 SQL 语句、分组统计查询语句;设计单个表针对自身的连接查询,设计多个表的连接查询。理解和掌握 SQL 查询语句各个字句的特点和作用,按照 SQL 程序设计规范写出具体的 SQL 查询语句,并调试通过。
说明:简单地说,SQL 程序设计规范包含 SQL 关键字大写、表名、属性名、存储过程名等标识符大小写混合、SQL 程序书写缩紧排列等变成规范。
1.2.3 实验重点和难点
实验重点:分组统计查询、单表自身连接查询、多表连接查询。
实验难点:区分元组过滤条件和分组过滤条件;确定连接属性,正确设计连接条件。
1.2.4 实验内容记录
1.2.4.1 单表查询(查询)
- 查询部门信息。
SELECT dept_no, dept_name FROM departments; 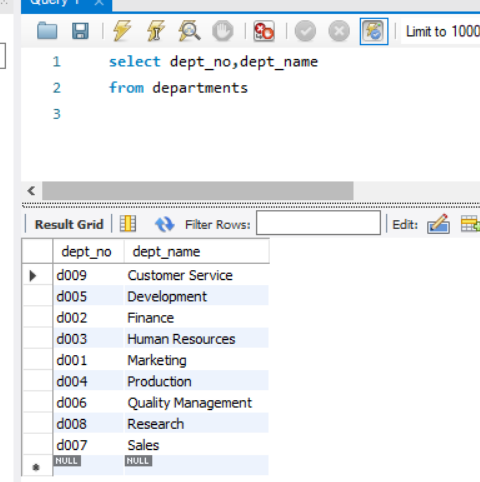
1.2.4.2 单表查询(选择)
- 查询雇佣日期为 1990-01-01 的所有男性员工信息。
SELECT * FROM employees WHERE hire_date='1990-01-01' AND gender='M'; 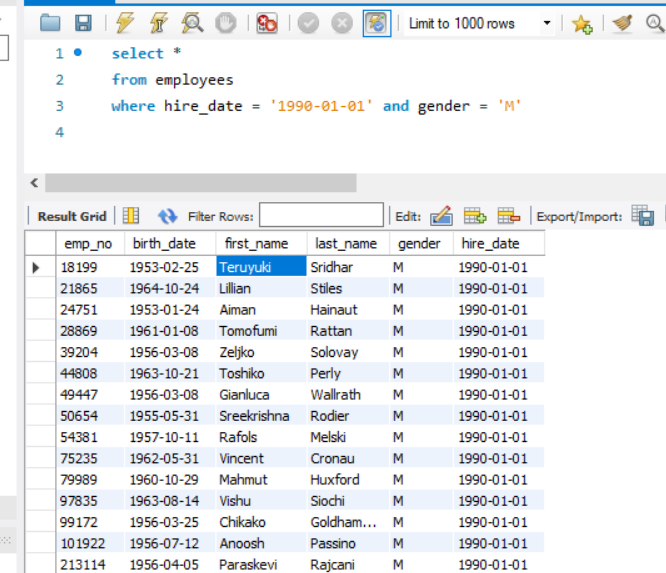
1.2.4.3 不带分组过滤条件的分组统计查询
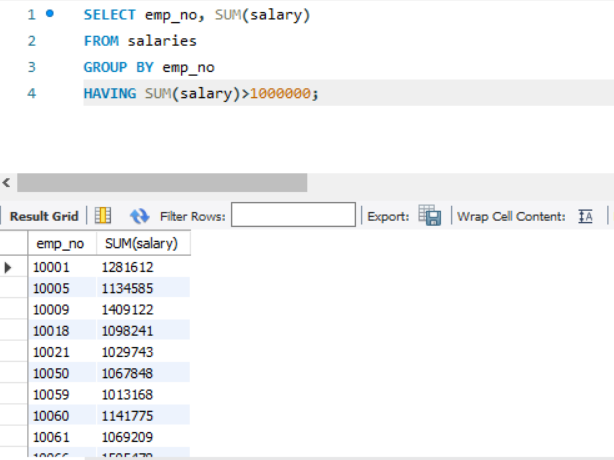
- 查询所有员工的工资总额。
SELECT emp_no, SUM(salary) FROM salaries GROUP BY emp_no; 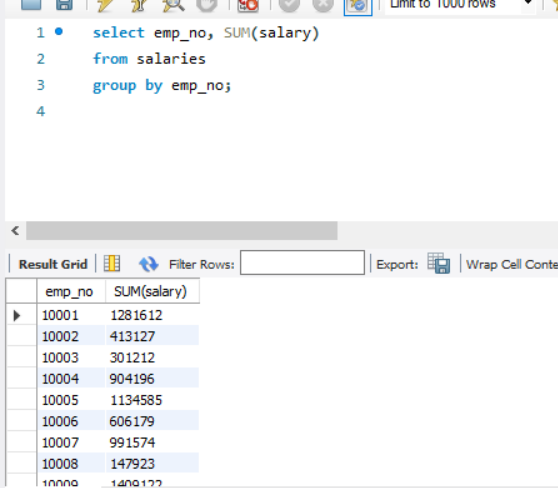
1.2.4.4 带分组过滤条件的分组统计查询
- 查询工资总额不低于 100 万的所有员工的工资总额。
SELECT emp_no, SUM(salary) FROM salaries GROUP BY emp_no HAVING SUM(salary) >= 1000000;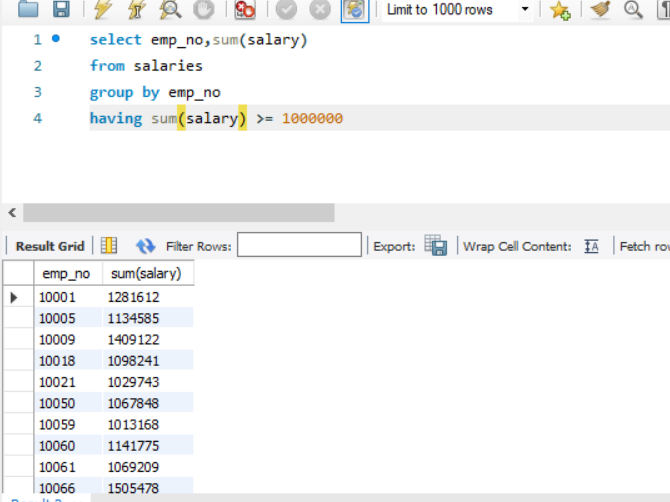
1.2.4.5 两表连接查询(普通连接)
- 查询所有 1990 年入职的员工职位。
SELECT DISTINCT e.emp_no, first_name, last_name, hire_date, title FROM employees e, titles t WHERE e.emp_no=t.emp_no AND hire_date BETWEEN '1990-01-01' AND '1990-12-31';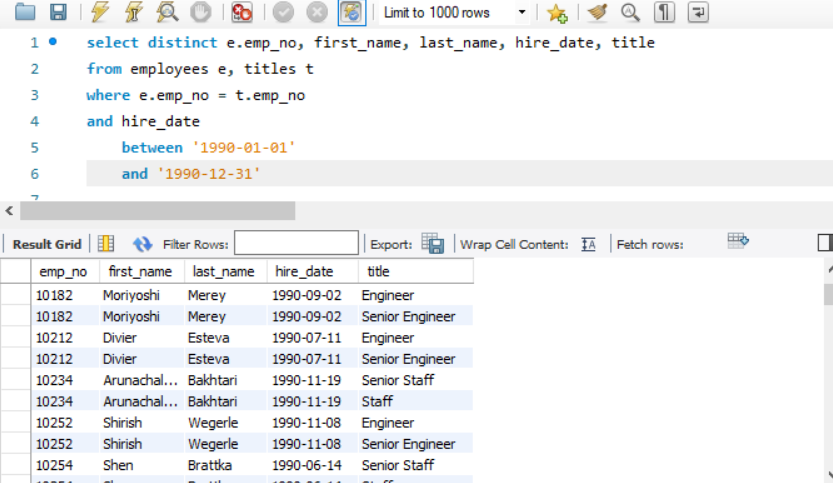
1.2.5 思考
- 不在 GROUP BY 子句中出现的属性,是否可以出现在 SELECT 子句中?请举例并上机验证。
析:
GROUP BY 用于按相同属性分组,用来细化聚集函数的作用对象。使用 GROUP BY 子句后,查询结果集中每个分组只有一个元组,因此对于没有出现在 GROUP BY 子句中的属性,在 SELECT 子句中出现会出现问题。举例如:
查询所有员工的总工资
1 | SELECT emp_no, SUM(salary), salary |
**Error Code**: 1055. Expression #3 of SELECT list is not in GROUP BY clause and **contains nonaggregated column 'new_schema.salaries.salary' which is not functionally dependent on columns in GROUP BY clause**; this is incompatible with sql_mode=only_full_group_by
会出现报错情况,认为salary无法通过group by进行聚合
- 请举例说明分组统计查询中 WHERE 和 HAVING 有何区别?
两者区别在于作用对象不同,WHERE 作用于基本表或视图,HAVING 作用于组。举例如:
1 | SELECT emp_no, SUM(salary) |
1 | SELECT emp_no, SUM(salary) |
**ERROR** 1111 (HY000): Invalid use of group function
WHERE 子句中不能使用聚集函数作为条件表达式。
连接查询速度是影响关系数据库性能的关键因素。请讨论如何提高连接查询速度,并进行实验验证。
连接操作中最慢的是嵌套循环算法,如果有序,或者有索引,则可以进行优化。
如果连接条件只有等值比较,则容易优化(有序双指针比较);
如果连接条件能够建立索引,且事先已建立索引,则容易优化;
举例:
查询在 1992-01-01 入职的员工及其所在部门信息。
1 | SELECT COUNT(*) FROM ( |
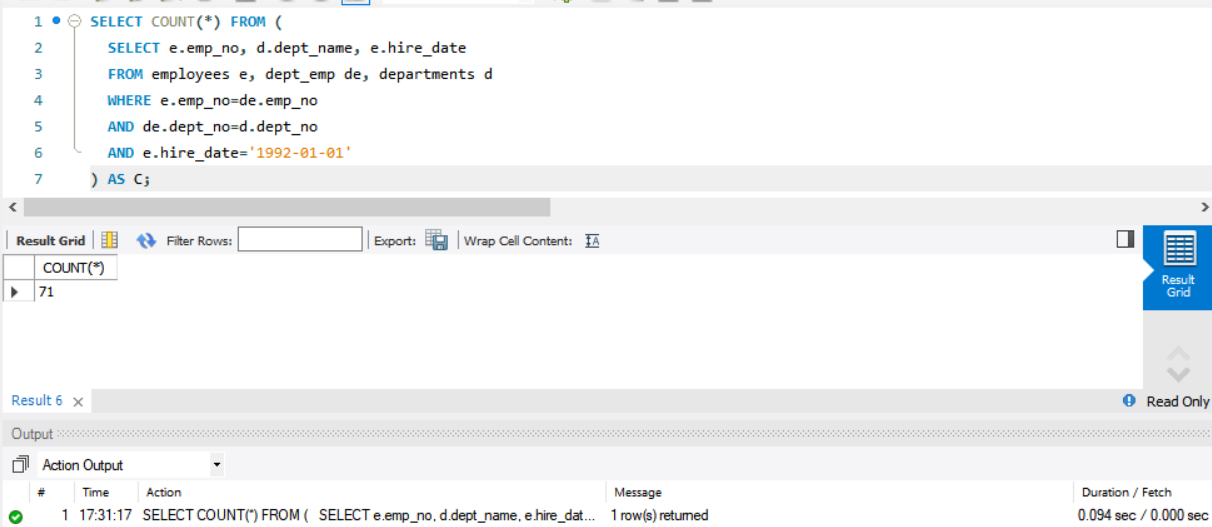
1 | SELECT COUNT(*) FROM ( |
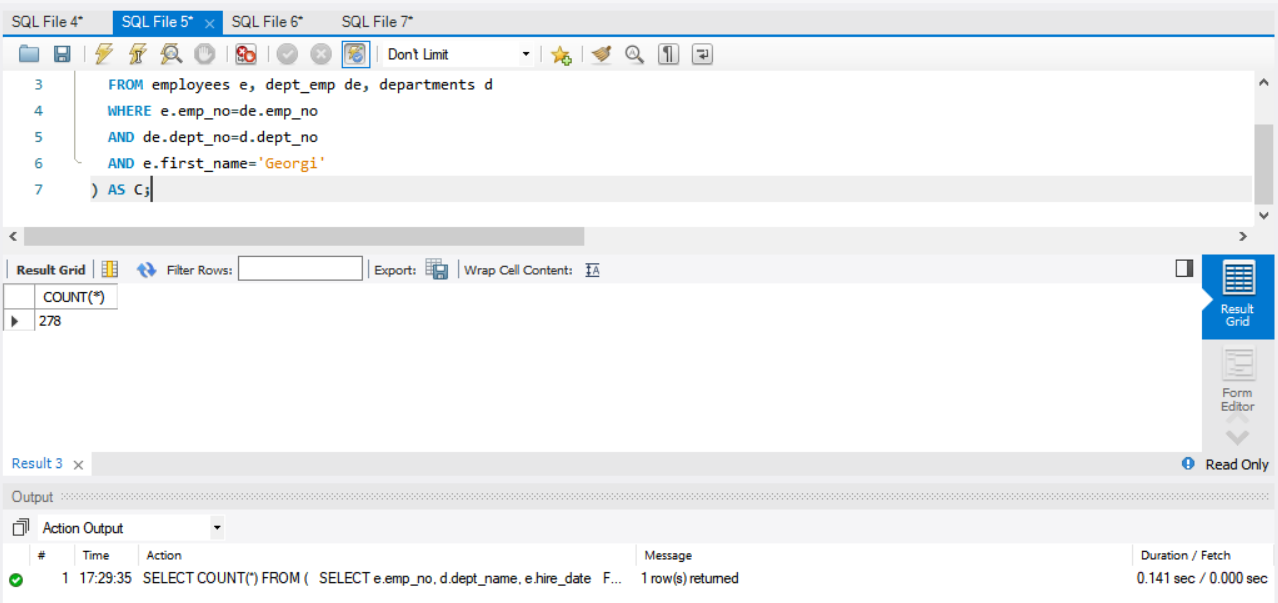
1 | SELECT COUNT(*) FROM ( |
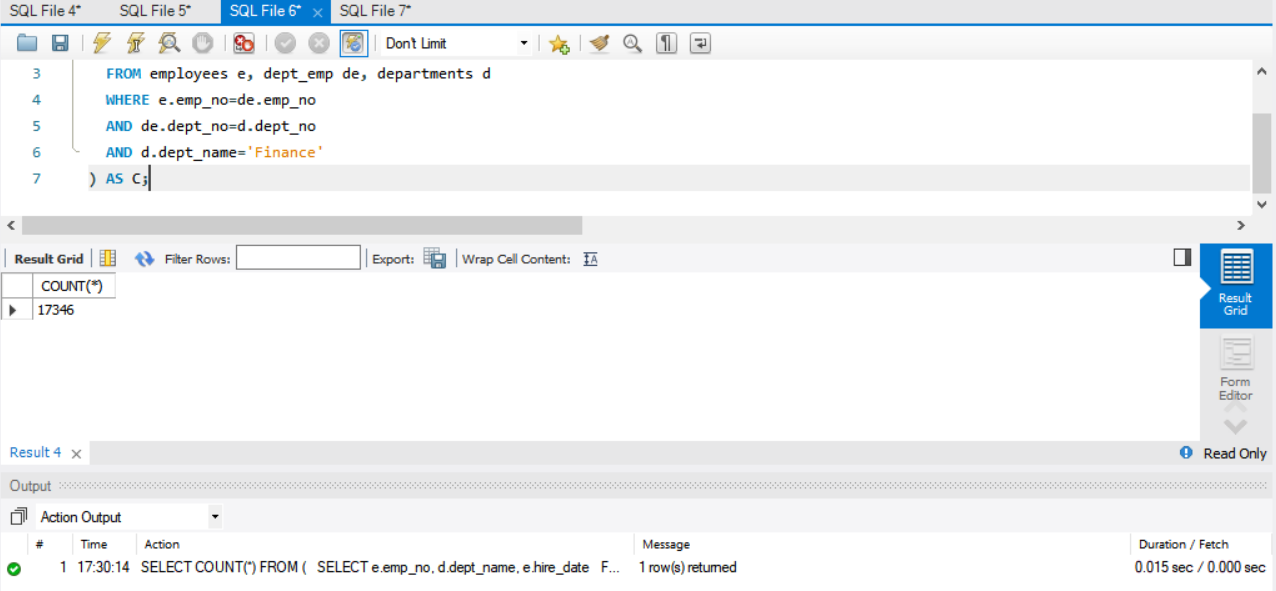
可以看出,对于存在 UNIQUE 完整性限制的属性,连接速度提升非常大。