第三课 Function
BNF
- Associativity 结合性
- Priority
- Type conversion 混合类型运算时的数据类型转换(决定了二进制序列的解释方式)
- Evaluation order 求值次序 = > side effect 从左往右和从右往左算的时候结果不一样 (表达式的副作用没有用,函数的副作用才有用)
异常:Exception
特征:
- 可以预见到
- 无法避免
类型:
- Side effect
- 精度问题:类型转换涉及精度变换 doube -> int 窄转换
- Overflow
Expression
许多改进都是为了更方便的写程序,减少错误
- auto - 编译器根据表达式确定数据类型,避免数据类型名的重复。关键字的引入需要综合考虑,如果太短,会造成已有的变量名冲突,如果太长,则会不受欢迎
- Range-for
for(auto i:vector )- for
trivial错误 - 避免for循环的边界错误
- for
- Uniform Initialization 结构化和OO的初始化不一致
- Constexpr 利用纯函数不能受到状态的影响
Switch
以空间换时间:
用表存储switch的所有结果,实现一次比较找到目标
可以用if else 、表、平衡二叉树表示
Function
内存

Data 全局数据区:下界清楚,存放全局变量
栈:存放函数。可以重复利用有限空间,符合局部性原则,由编译器控制生死
堆:存放动态变量,malloc(),heap中的管理由程序员接管
栈和堆的大小由程序运行的逻辑决定,所以堆从下往上,栈从上往下
代码区:以function为基本单位,函数有完整的逻辑。
函数有定义点和调用点。所以函数定义时也需要存储在符号表中。节省了重复代码的出现。
RAII机制
DLL按需所取,牺牲时间,节省空间,但是不是全平台自适应,因为不一定有对应的code
static:永远分配 - 》 给予固定空间:无法实现递归,好处是减少了和内存之间的交互
函数的调用:后进先出 – > 表达能力更强(可以递归),但是在数据区付出了更多的COST 代价
符号表的建立:
- 当看到使用点时,在符号表中找到对应的地址,取值使用
- 当和lib进行link时,找到需要的变量

- C里面不允许函数重载,所以可以用fun代表 。但是如果重载,需要在符号表中嵌入参数
 4代表后面四个字节为函数名,i代表int,d代表double => 使用Lib需要注意什么? => 添加接口
4代表后面四个字节为函数名,i代表int,d代表double => 使用Lib需要注意什么? => 添加接口 **extern "C" **=> 判断有无name mangling
函数的COST
函数:复用机制+自顶向下,逐步求精
指令开销+数据开销
能在不降低可读性的前提下,降低COST吗?
- 在src源代码中写的是函数
- 在经过编译器编译后,将函数代码直接放在对应的代码块中,不产生函数调用,省去了压栈出栈的过程
缺点:
- 替换后代码会拉长
- 代码段的拉长会带来危害
程序员主动使用inline,向编译器提出申请,直接把函数对应的代码放入源代码中 => 因为不是完美的,所以需要程序员自己提出申请。但是,提出申请后,编译器有权驳回
程序员使用virtual 提出dynamic binding,副作用:效率较低,以低效率获得语言的灵活性。不像java,全部默认为dynamic binding。 Programmer can be trusted
原则
- 定义不允许嵌套
- 先定义后使用:给描述以约束,同时提高编译器的效率:编译器是一个个cpp扫描的
内联函数 inline
要明智的申请inline函数
目的
提高可读性,提高效率
实现方法
编译系统将为 inline 函数创建一段代码,在调用点,以相应的代码替换
缺点
- 无法实现递归,语言表达能力降低
- 代码段的增加会带来效率的降低
- 函数指针
适用场景
- 函数的长度短小,避免替代带来额外开销
- 使用频繁的代码
- 简单的代码:不要有多个转移接口的结构
构造函数适合inline函数。构造函数放入class的定义中,会自动申请inline
局部性原则
为什么代码段增大会出现问题?为什么不能有复杂的数据结构?
时间局部性,空间局部性 => 每一次都是调用相关的放入内存,如果有额外需要,再通过虚拟内存管理,从硬盘中获得对应数据
因为内存是分级的,附近的代码放入Cache中(高速缓存)。原来的Cache中,为x=1 ;f(1) ;,一直都在Cache中循环。但如果f(1)替代为Ablock,因为Cache有限,block中的有些代码在Cache中,有些不在,需要不断调换block在Cache中的代码。Cache中会产生抖动,即调度的cost
缺点
- 增大目标代码
- 病态的换页
- 降低指令快取装置的命中率
函数指针 ??
实现framework
函数的执行机制
- 建立被调用函数的栈空间
- 参数传递

- 值传递
- 引用传递

- 保存调用函数的运行状态
- 将控制转交给被调用函数
局部变量要主动初始化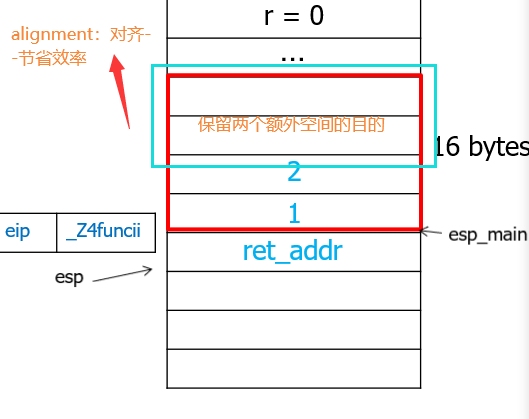
运行时环境
_cdecl
_stdcall
参数的空间是由被调用者返回,不支持参数是可变长的 — 适合平台的协作
- _cdecl:参数的空间是由调用者返回,支持参数是可变长的 例如:
**printf(char *s, ...) **
可变参数的缺点:
**printf("hi ",num1,num2 )**有缺陷:没有用num1 num2,却可以拿到对应的值,不安全- 会增大代码的长度。因为调用是复用多次的,所以积少成多了
cout中<<是双目操作符,实现原理是操作符重载,而不是可变参数的调用
调用者还和被调用者还
差别:发生在返回时
_fastcall
参数传递放入的是寄存器中,而不是push到栈中
瓶颈:
寄存器数量有限,每用一个寄存器,寄存器中原有的值都要保存下来
_thiscall
略
传递方式
Call by name

结果: a[2] = 3
Call by value-result

函数原型
原型:void f(int , int)
编译器在调用函数时,能根据原型生成正确的代码
如果编译没找到时,也会在link时找到
- 遵循先定义后使用原则
- 自由安排函数定义位置
- 只需参数类型,无需参数名称
- 编译器检查
函数重载
原则:
- 名同,参数不同
- 返回值类型不作为区别重载函数的依据
匹配原则
- 会产生二义性:10可以转为long,也可以转为double
**ambiguous** - 严格
- 内部转换
- 用户定义的转换
意义:多态一名多用 属于语言的特征
默认参数
- 默认参数的声明
- 函数原型中给出
int f(int =1,int =2,int =3)原型决定默认参数 - 先定义的函数给出
- 函数原型中给出
- 默认参数的顺序
- 默认参数与函数重载
攻击
- 提供坏地址 = > 指令和数据为正交
- 不自动写代码,而是选择指令去运行(借刀杀人)=> 内存地址的随机化,不会产生错误,只会产生异常