第八课 高速缓存器
- 对于直接映射的块交换还无法形成完整的逻辑自洽
- 如何求的块内地址、标记、cache行号
- 如何根据主存地址去寻找
寄存器和Cache就集成在CPU中了
内存墙:CPU的速度比内存(受限于电容)的速度快得多
解决:CPU和内存之间增加Cache
工作
工作原理
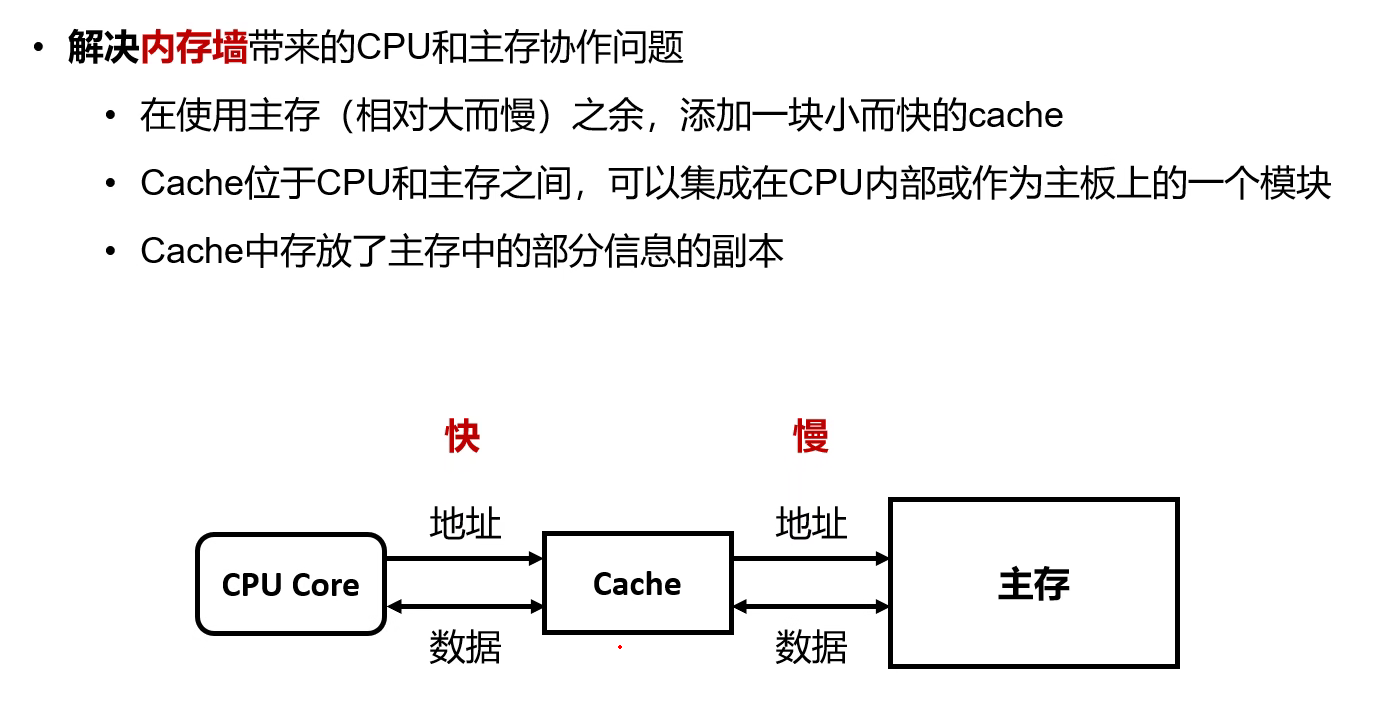
工作流程
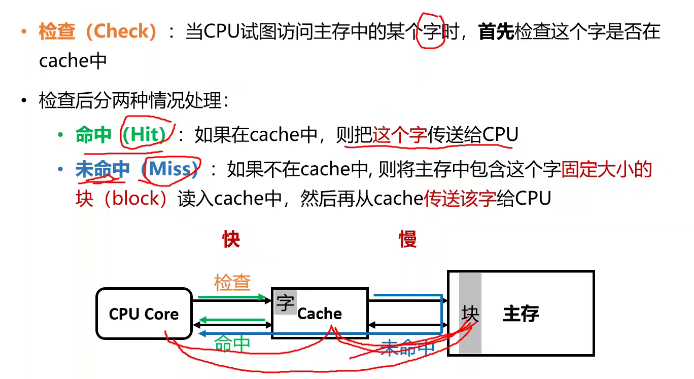
- 如何判断是命中还是未命中?
- 如果未命中,为什么不直接把所需要的字从内存传送到CPU?
- 时间局部性
- 如果未命中,为什么从内存中读入一个块而不只读入一个字?
- 空间局部性
- 使用
Cache后需要更多的操作,为什么还可以节省时间?
命中VS未命中

程序访问的局部性原理

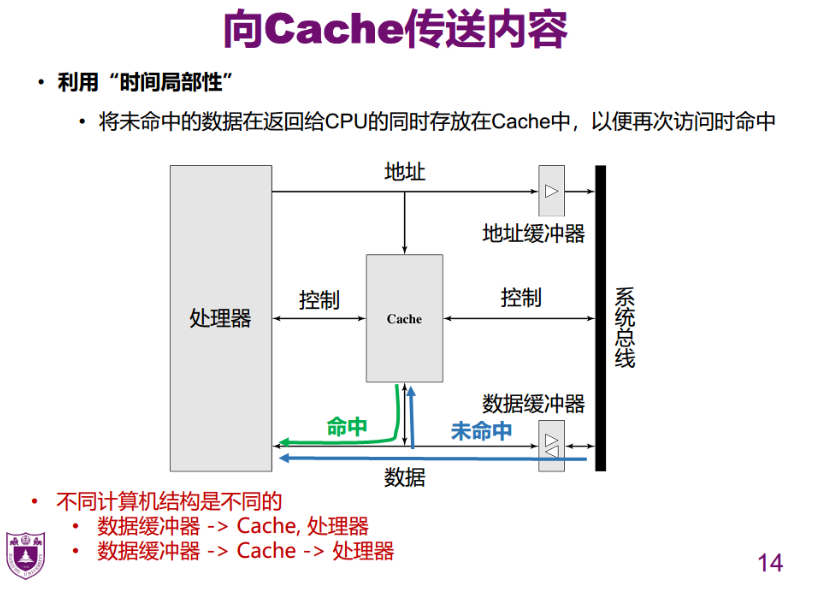
- 把块给
Cache,把字给处理器 - 两种方式时间开销上无较大差异
- 系统总线代表主存,主存速度很慢,而
CPU会一直申请数据,所以需要缓冲器
因为会重复访问特定的数据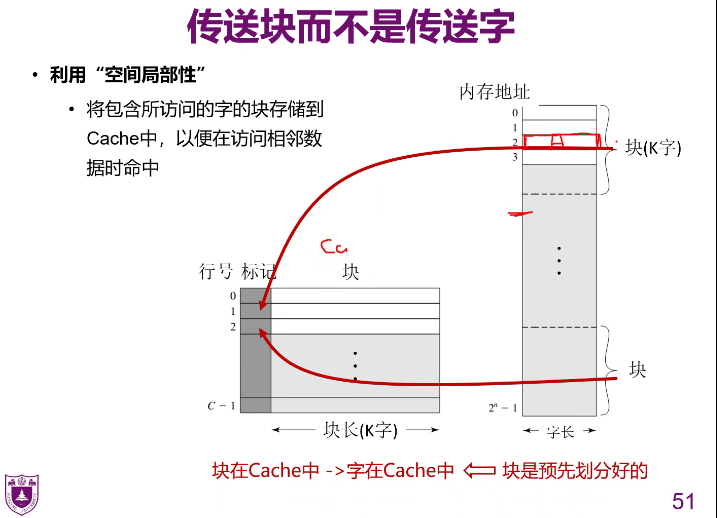
平均访问时间
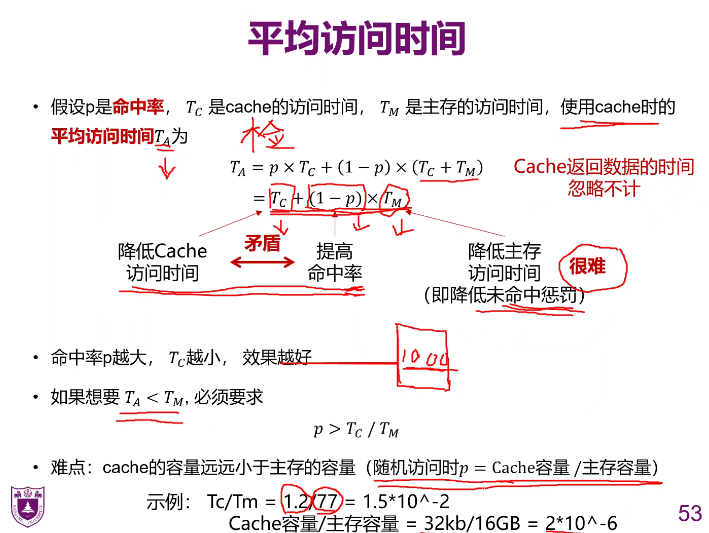
Tc:做的是检查Ta = 检查时间+访问主存的时间(1-p 需要访问)
Cache未命中原因

Cache的设计要素
容量

映射功能
直接映射
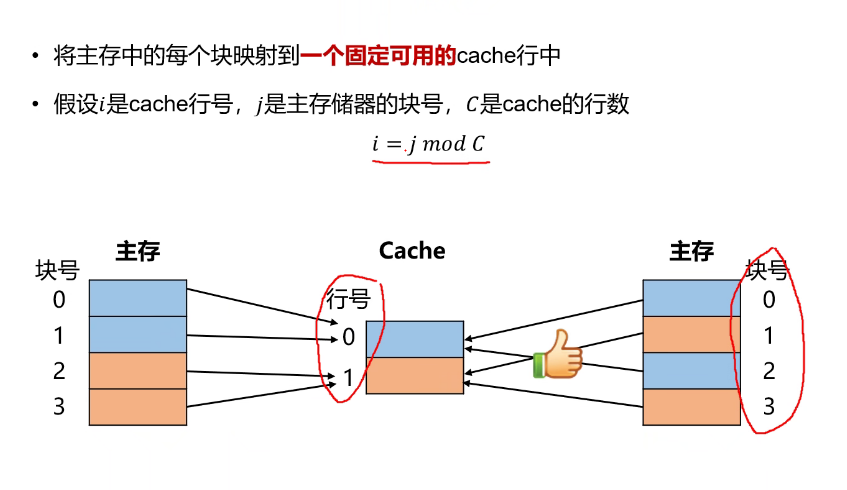
使用地址的高2位就可以 指向具体的行
指向具体的行**M是128/8=16,C=4 所以n=2:**
16个块,有4行,所以一行中有4个块,所以需要2位标记
CPU寻找主存,通过主存地址进行寻找
一个块包含很多字,一个块对应的是cache中的一行。
所以要通过块内地址找到块中具体的字在哪里。
- 什么是每行包含8个字:一个块包含了八个字,需要用3位二进制进行。这里的字可以理解为一个数据单元。
- 主存中包含128个字:所以主存地址为7位
- 主存和缓存是按块进行存储的
- 块的大小是相同的

命中了的话再根据子块内地址找到对应的字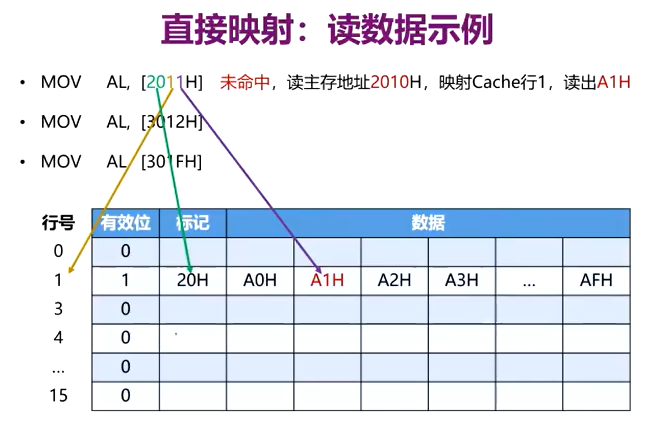
- 因为只有16行,所以只需要1位表示就行(前提是16进制)
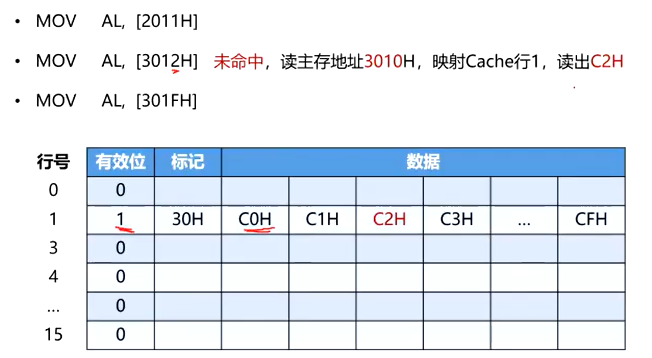
总结

全相联映射

总结
代价:
- 需要知道哪一行是空的
- 要访问每一行,所以容量增大的话,则
Tc显著增加

组关联映射


总结

比较

替换算法

可以通过软件进行模拟,例如解决缓存问题。但本身是通过硬件实现
再次访问的概率相较于其他行更低?
最近最少使用算法 LRU?

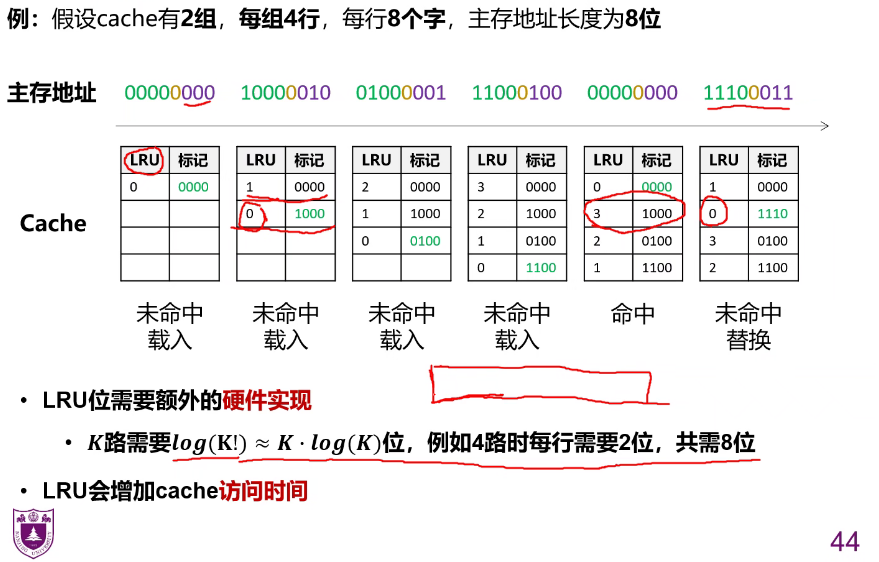
先进先出算法


最不经常使用算法 LFU

随机替换算法
假设的情况和真正情况的符合度较高。所有能够进入Cache的数据,本身都是“万里挑一的”
写策略
缓存命中时的写策略
写直达

写回法

缓存未命中时的写策略
写不分配:对安全要求较高的
写分配:程序中隐含较多时间和空间的局部性
行大小

不是违反了时间关系,而是违反了时间局部性:重复访问存储在相同位置的信息,那么每一次找都要找很久
反空间局部性:**重复
Cache数目

冯诺依曼:指令和数据不区分。根据阶段进行区分
对与Cache,数据很快会把Cache填满,而指令也会频繁使用-都受到局部性的支配,所以需要消除竞争关系,避免冲突失效
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 丁丁的小窝(*^_^*)!